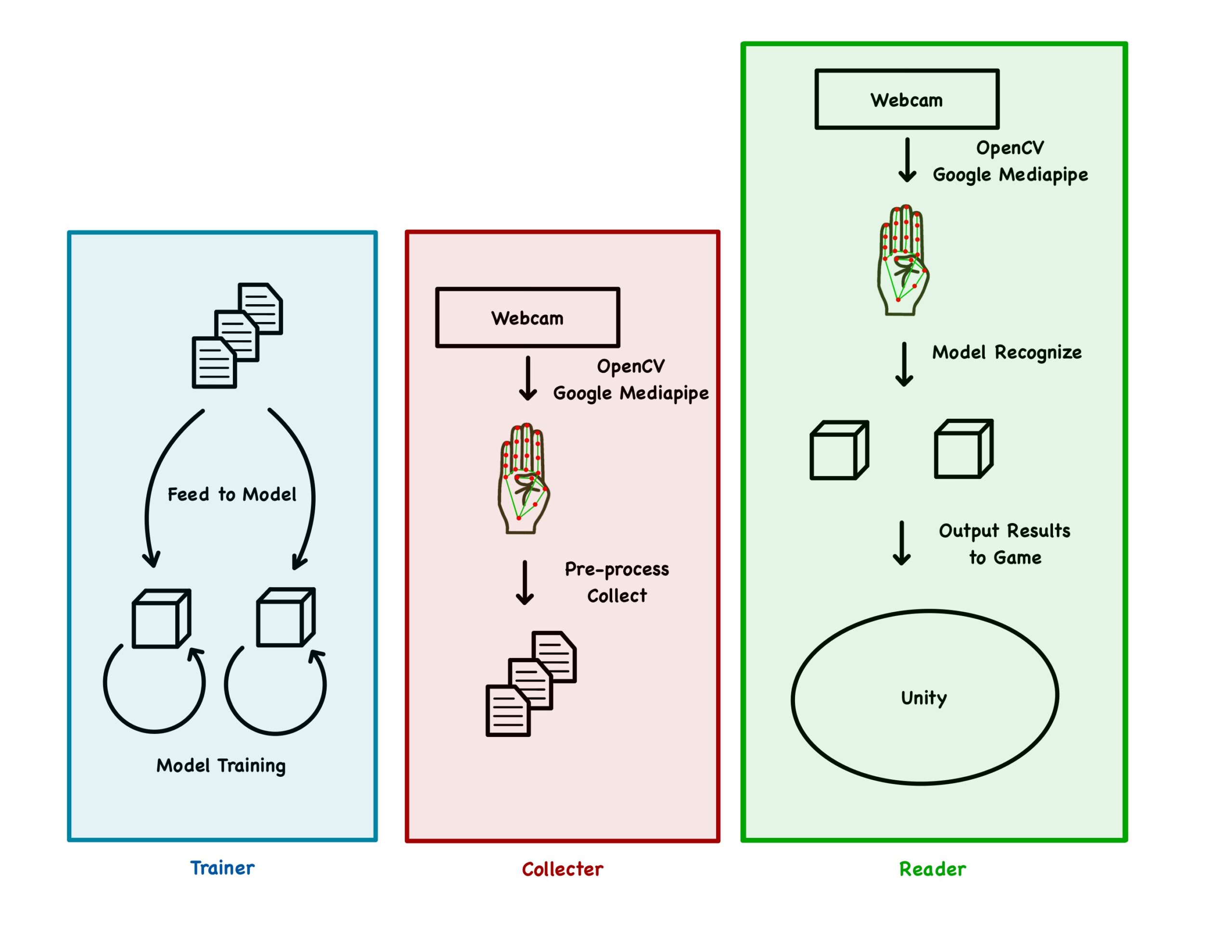
Recap
We used a webcam with OpenCV and Google Mediapipe to identify human hands in real time. We then extract the landmarks coordinates, pre-processed it, and saved it into a csv file. We trained an Artificial Neural Network Machine Learning model to map the landmarks coordinates with a corresponding gesture. Finally, we use the model to recognize hand signs by the player in front of the camera and input data relating to the hands through our game.
Retrain the Model
After halves, we started to collect data from all of the team members (Figure 1.1), collecting a dataset with different hand sizes, hand shapes and slightly different representations for signs. We collected data by extracting a collector module from the whole process and installed that module in different machines. This accelerated the data collecting process and resulted a more diverse dataset for our model.

We consulted a sign language expert Erik Pinter to ensure we have the correct sign representation in real case fingerspelling scenarios to keep the dataset fed to the model robust and accurate.


Motion Signs Research
After being able to recognize 24 signs, we worked on the remaining two (J and Z) which requires motion. To achieve this, we use another NN architecture called Recurrent Neural Network (Figure 2.1), to train data with time sequences data.
A Recurrent Neural Network, also known as RNN, is a type of Neural Network where the output from the previous step is fed as input to the current step. In traditional neural networks, all the inputs and outputs are independent of each other. Still, in cases when it is required to predict dependent data such as words in sentences or sequences in time series data. The main and most important feature of RNN is its Hidden state, which remembers some information about a sequence. The state is also referred to as Memory State since it remembers the previous input to the network.
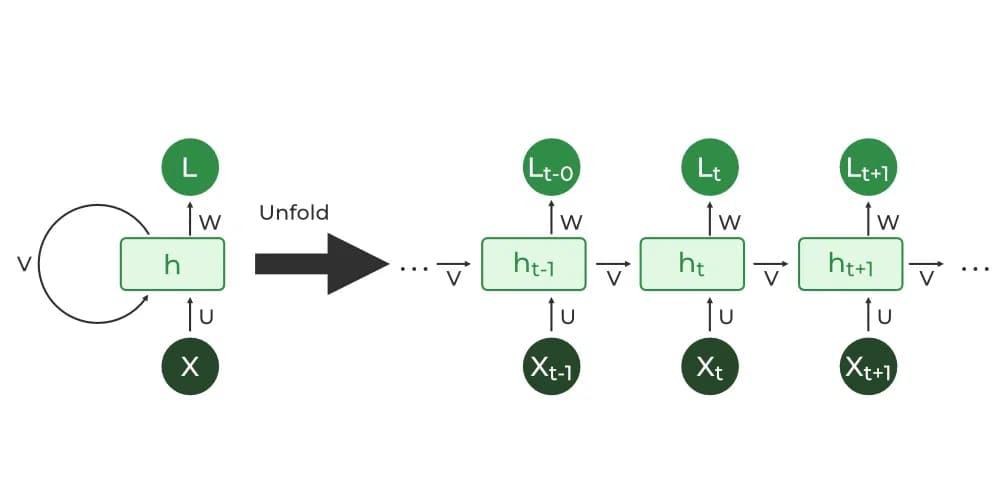
A traditional RNN has a single hidden state that is passed through time, which can make it difficult for the network to learn long-term dependencies. Therefore we chose another version of RNN called LSTM to overcome this kind of limited long-term dependency learning issue.
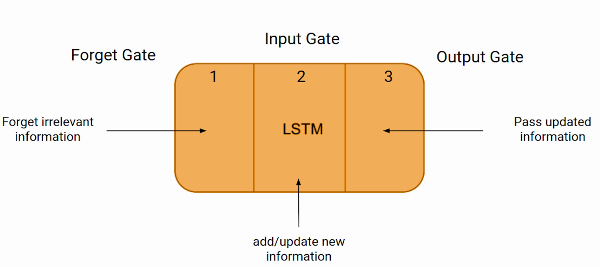
LSTM, also known as Long-Term-Short-Memory, is an improved version of recurrent neural network well-suited for sequence prediction tasks and excels in capturing long-term dependencies. LSTMs address the limited long-term dependency learning problem by introducing a memory cell, which is a container that can hold information for an extended period and its applications extend to tasks involving time series and sequences, such as machine translation, speech recognition and image/video analysis.
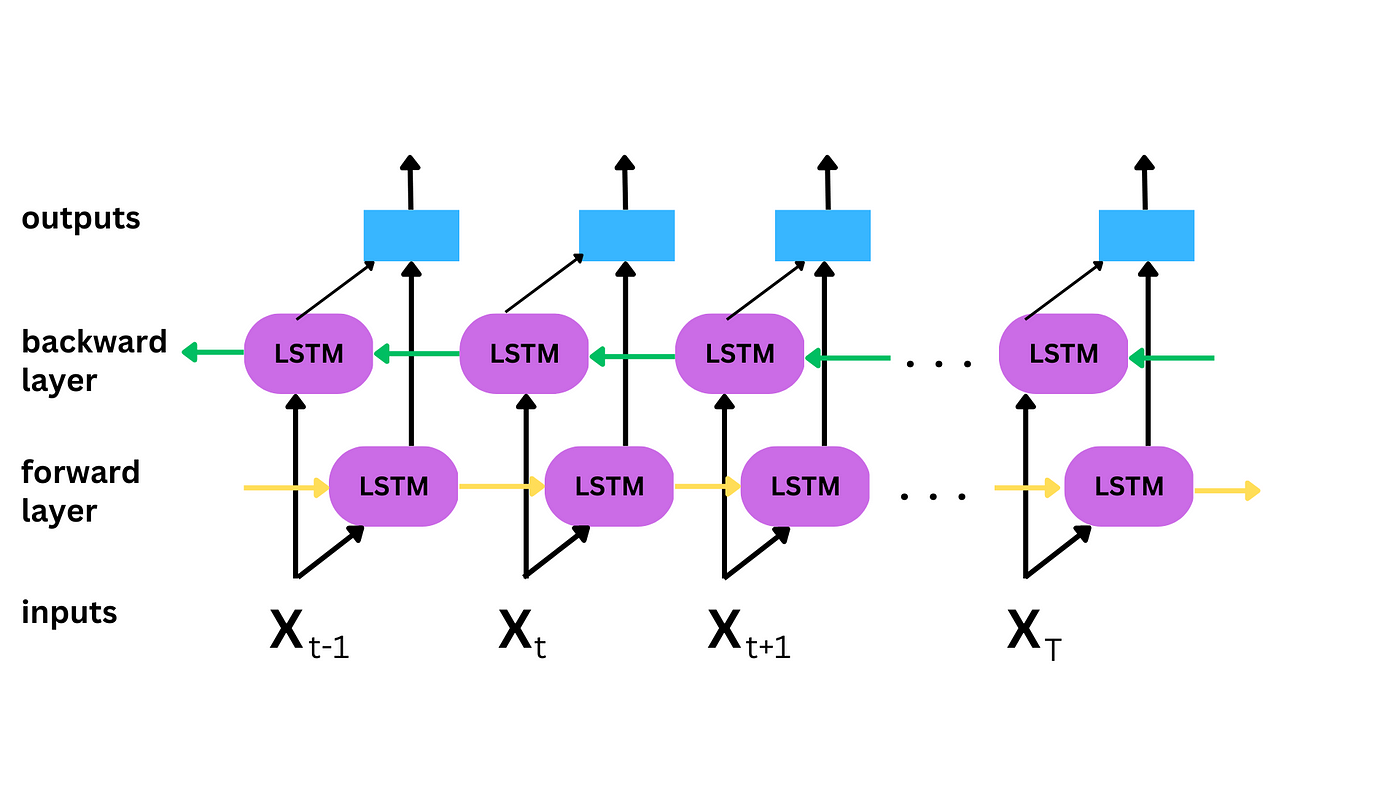
The specific network we used is a Bidirectional LSTM, that processes sequential data both forward and backwards. We experimented both LSTM and BiLSTM for sign recognizing, there’s no big difference in recognizing J and Z, but might have potential difference for more complex signs if one adds more signs in the future.
Motion Signs Recognition
By observing the sign J and Z, we found out that both of them require to point out a certain finger to do movements. Therefore, we set up a sequence queue to keep track for one specific landmark point aiming by using less data for training a RNN (Figure 3.1). We tracked the pinky finger tip for J and the index finger tip for Z, and we extracted the coordinates of the tip from each camera frame and fed these data into a LSTM.
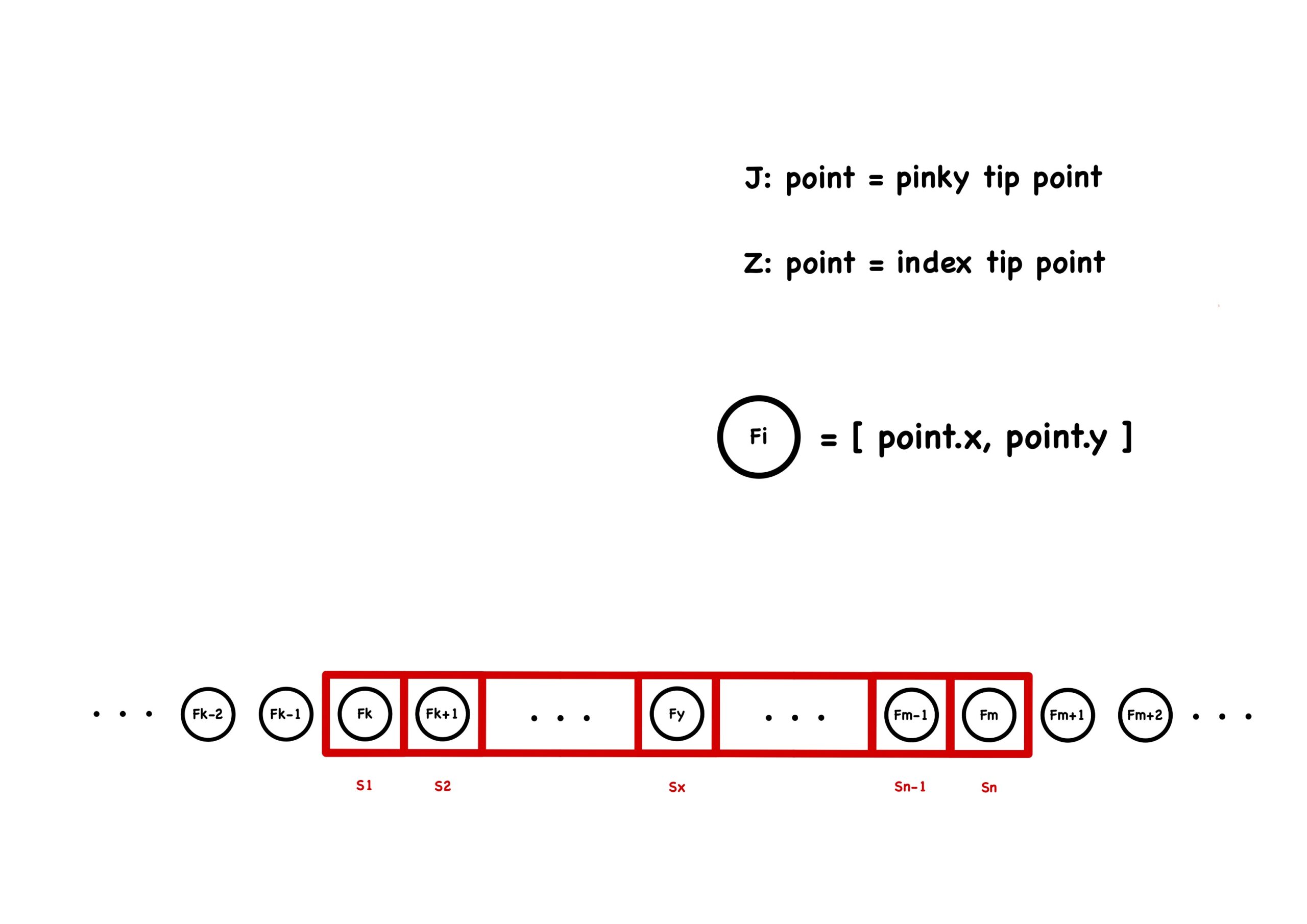
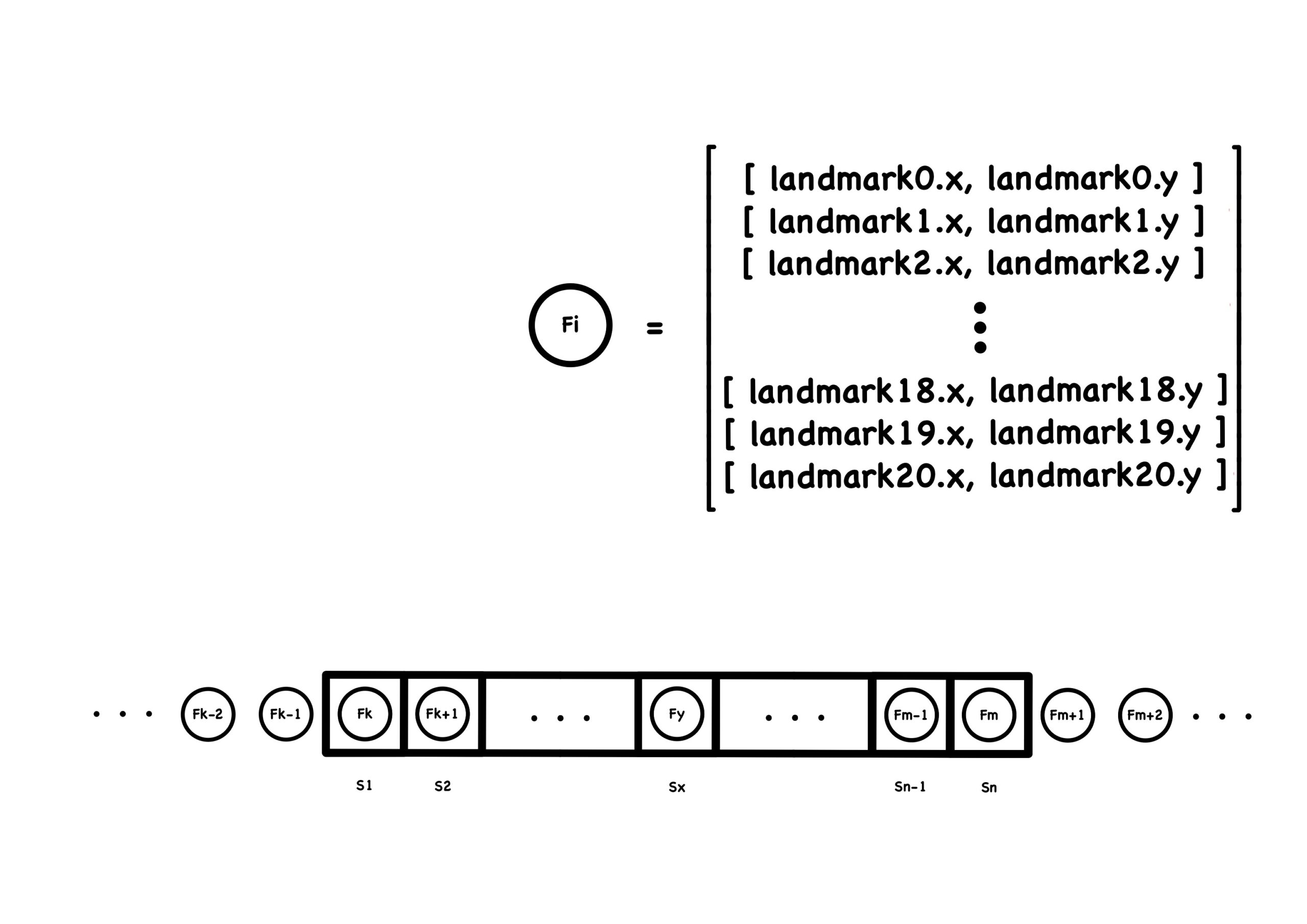
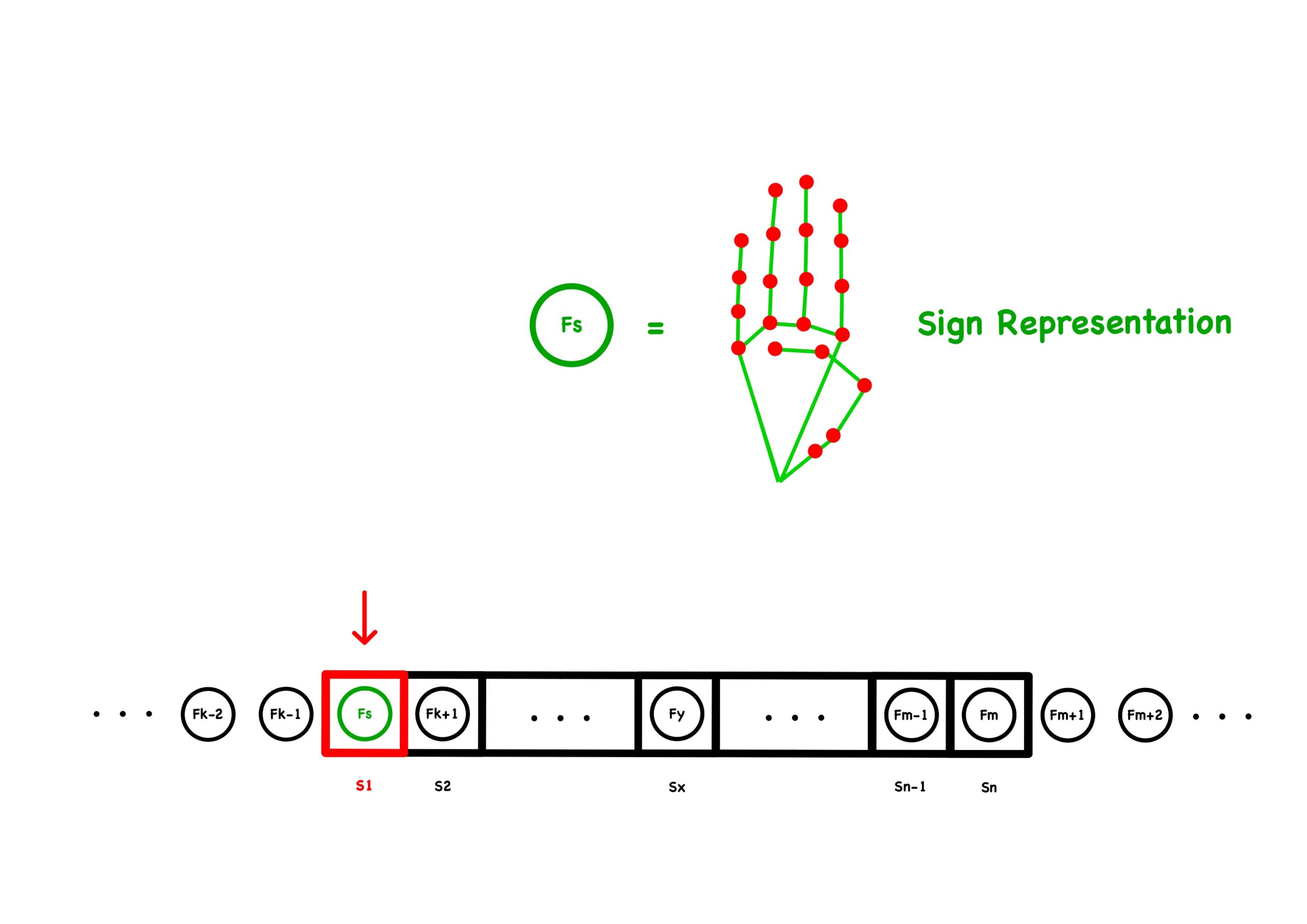
The main advantage of this approach is that it’s simple, easy to train and less data is needed. However, after testing this simple approach, we found that we could use different representation to “trick” the model to output a letter, as long as the single point obeys the sequence we trained the model with. For example, we can get the same result when pointing out the index finger to draw a J as pointing out the pinky finger to draw a J. So, instead of tracking one point, we tracked all the points on our hand, to make sure the whole hand follows the path we desired. Another advantage for tracking the whole hand is that it’s easier to expand new hand signs in the future and doesn’t require tracking specific points for a given sign.
However, we discovered a flaw during playtesting with our instructor Tom. We found out with a small difference with the representation of a motion sign, the model will still output the letter with not exactly the corresponding sign we wanted the player to do. For example, we can get the same result when opening our palm (pointing out all five fingers) drawing a J as pointing only the pinky finger to draw a J.
To fix this, we changed the data format to ensure that the first sequence, acting as a prerequisite, is represented as a specific sign, and the sequences following from that first sequence sign is the same as the real representation of the sign. Since the first sequence from the original format is all zeros(normalized based on the first sequence), we could store the first sequence sign representation in the first sequence position to utilize space and save time for recollecting the data.
A potential data reformat is to do similar operations with all the sequences, but due to time constraints and simplicity, we just changed the first sequence.
Overfitting
After training all the model with all of our data, we were expecting the model capable of telling the difference between similar signs like M and N, also having a list of confidence scores representing how likely a sign representation would be interpreted as a certain letter.
This is a optimal simulated graph of the model recognizing a certain sign, we will just show M & N for explanation. Whenever a model recieves a sign, there will be a point landing on this graph, if a point lands on a colored region, the model will intepret (give scores to) this sign as a certain letter. The darker the colored region, the higher the score will be given to the letter for that sign.
We also want the model to be good at interpreting ambiguous signs. For example, if we put our thumb directly under our ring finger, we were hoping that our model would interpret this sign as both M & N with some equal confidence score (red point).
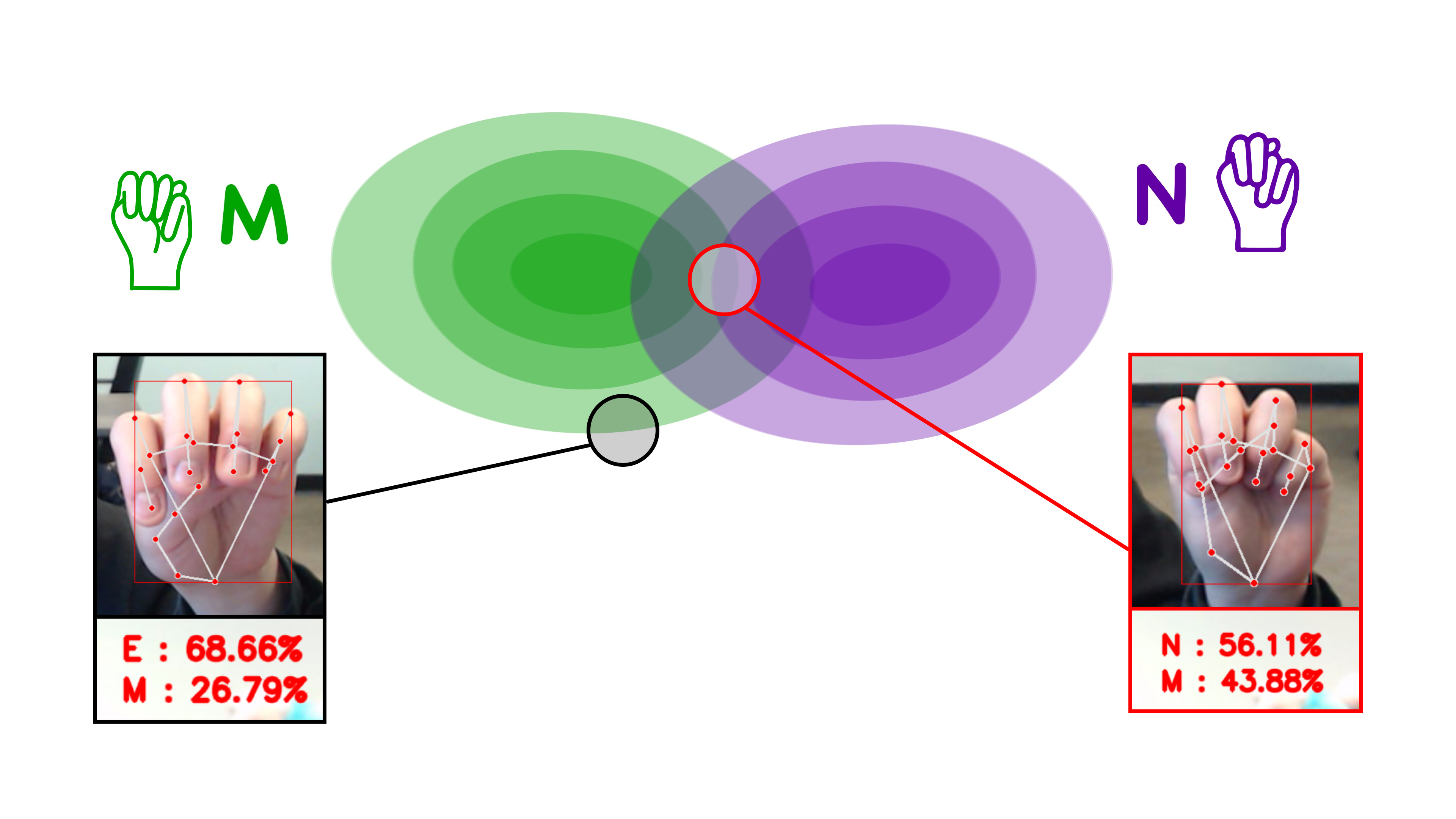
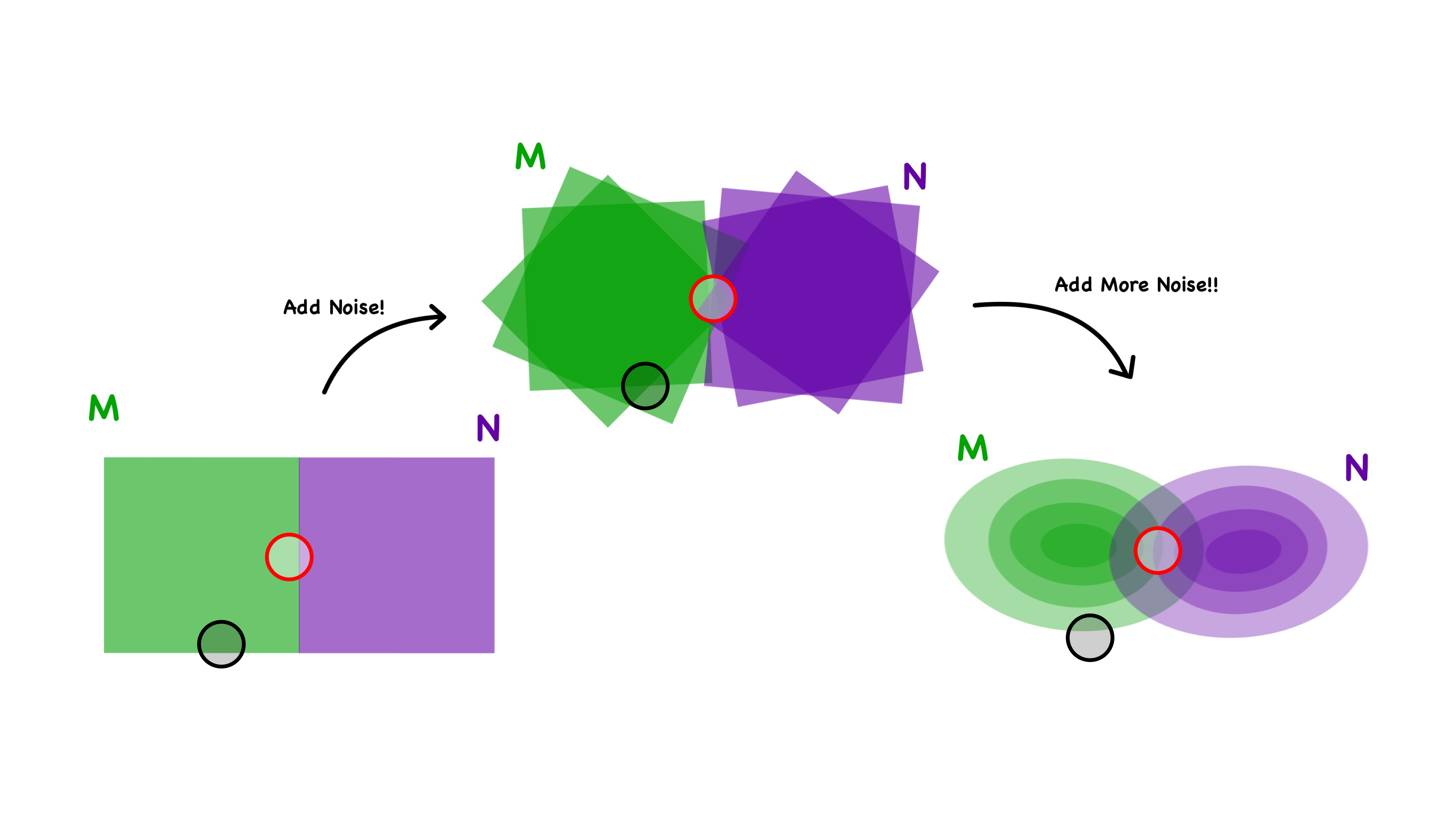
However, after training, we have our models suffering in a situation called overfitting.
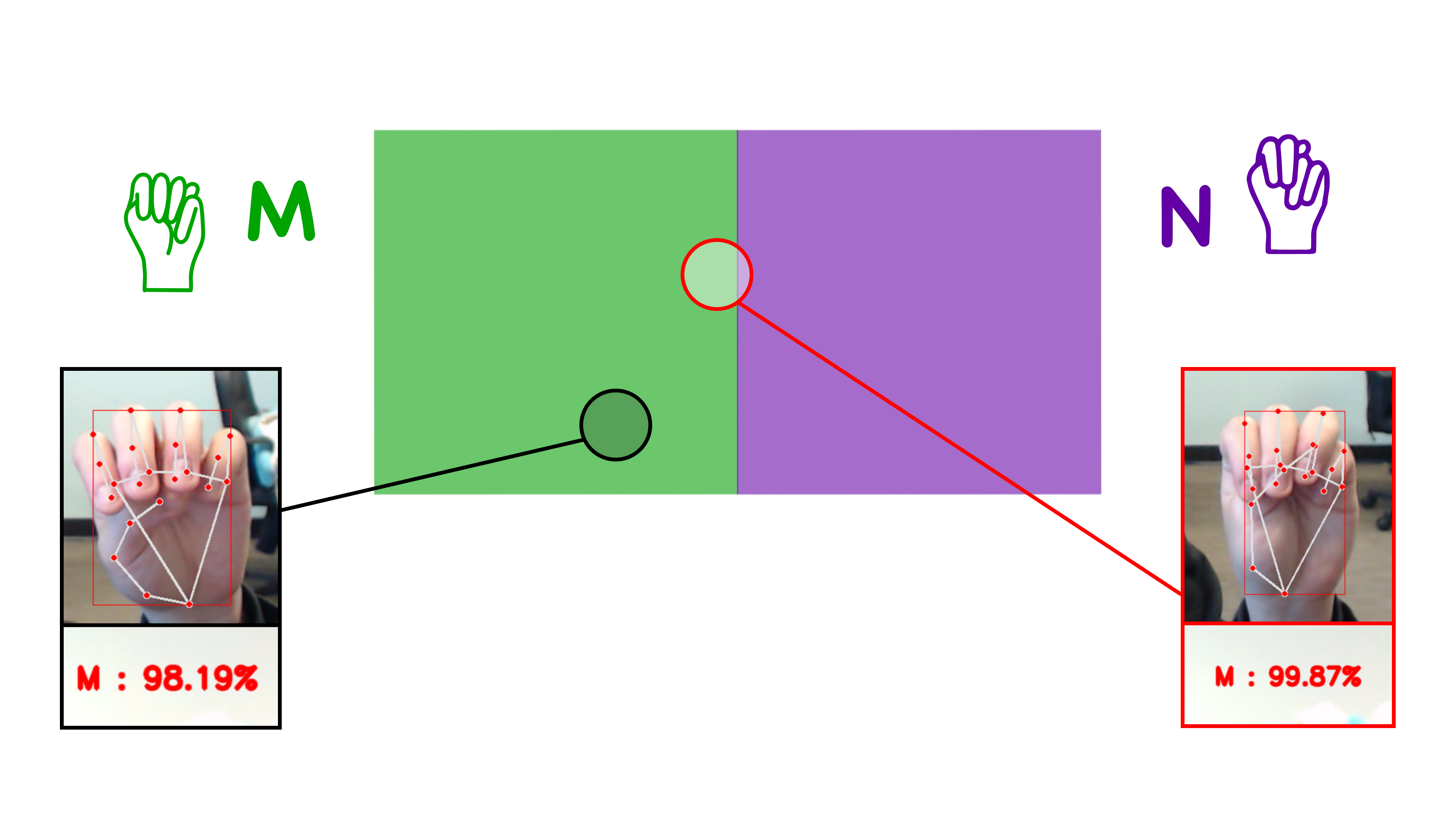
Overfitting in Machine Learning means overtraining a model, which result a model having bad abitlities to generalize with unseen data. In our case, we have a overfitted model that couldn’t distinguish between ambiguous representations of signs. For example, when we show a sign with ambiguous representations, the model will give us a confident answer which might be too strict/loose or even giving us a letter which is wrong.
To prevent this from happening, we applied some techniques like adding dropout layers and regularizers inside our neural network to drop out weights, also adding some noise data to prevent incorrect outputs. A more simple way to think about this is we used some methods to kind of question the model and teach the model to be humble when making predictions. We also split the training data to different portions to cross validate that our model is trained well, instead of overtraining or under training.
After fixing the overfitting problem, we now have a suitable-for-sign-language-learning hand sign tracker for our game.